
Tech Talk: Asynchronous Thinking for Microservice System Design
BY CHRIS MONSON
Introduction
Microservices are a useful tool for various reasons, such as independence of code evolution and system resiliency during network events (assuming a good distributed orchestration system like Kubernetes). Systems designed around microservices often need to move away from fully synchronous communication and into a more asynchronous model, but thinking about how that works can be a bit daunting, especially at first. Thankfully, there are ways of thinking about the problem—principles that you can apply—that help to demystify asynchronous designs.
Before we jump in, however, it’s worth mentioning that the space of possible distributed designs is huge. We are opinionated folks and we have our favorite approaches, but we are under no illusions that we have all of the answers, nor that you will get them all in a single article like this. We will therefore limit our attention to how to think about asynchronous design assuming that it is what you want already. As we do, here are a couple of principles to keep in mind:
Be flexible and pragmatic, not rigid and dogmatic.
Microservices are a tool, not a way of life. Don’t blindly trade maintainability for performance.
Know your constraints and how they interact. Act accordingly.
For example, asynchronous task management can be good for chunky tasks, bad for tiny ones, better for steady streams of work, worse for massive barrages of work. Know what works for you, and consider adjusting strategies to fit your actual resource and performance constraints. “Know thyself” applies strongly here.
Synchronous Design
Let’s ground this discussion in familiar terms, starting with basic synchronous communication. A good example of this is Internet websites, which are largely synchronous by design: your browser makes a request and waits for a response before processing it into the page that you eventually see. If you have ever gone to a website and complained that it took too long to load, you are experiencing wait time: a request might have gone out, but the response hasn’t yet come back.

Most microservice architectures actually use the same underlying protocol to communicate (HTTP), so this process plays out exactly the same way in synchronous communication between microservices: Service A asks something, Service B responds, and Service A has to wait for that response. The principle is this:
In a synchronous system, requesters wait for responders.
It’s important to note that this synchronous request causes resources to be used both on the request side and on the response side: the connection is held open the entire time, from request all the way through response.
Also important is the fact that sometimes synchronous communication is your only option, notably for web browsers, which are (approximately) only clients, not servers, and which are often on private networks using routers that only allow outgoing requests and related responses. The browser, however, is only an orienting example: the above diagram talks about the “client” and the “server”, but in your system these are going to be roles, not things. The client sends a request, the server receives a request; they might be the same piece of code.
Here we are limiting ourselves to a situation where microservices are used as a design tool for creating a larger system, so we assume that we have options: we aren’t limited to “this thing is only ever acting as a client and this other thing is only ever acting as a server.” Instead, many components do both: a server might make several requests to other servers in order to respond to a request from a client, for example, and that means the server is also acting as a client in some circumstances, in order to do its work.
With all of that out of the way, how should we think about synchronous techniques?
The Good
Synchronous designs are nice for both the client (e.g., your browser) and the server (e.g., serving a website), because they are straightforward to reason about and to just make work. Code flows in a fairly linear way on both ends:
The client: ask, wait, process response.
The server: receive, process, send response.
Both sides are written in a way that is simple, direct, and understandable. Furthermore, it doesn’t require a lot of cooperation between services: information about the request is in the same scope (and thread of execution) as the received response. We will see later on that this is not the case for asynchronous designs.
The Bad
Sometimes requests take a long time. When that happens, then both client and server hold a connection open, even though only one of them is doing useful work. But the difficulties don’t stop there.
What happens if the server instance handling the request has an internal error and crashes, or is evicted from the machine it is running on? In these cases, the client, who is waiting for a response, will need to time out and retry, or will simply not get an answer. The standard mitigation technique for this is usually a retried request, but there’s another difficulty. Consider this more complete (and common) diagram:

Here we see that the original requester (Service A) is waiting for an intermediate service (Service B in the diagram) to get something done. Let’s say, now, that the Service B quits while it is waiting for a response from Service C. The original requester, Service A, is stuck: B quit, but maybe the work would have been perfectly useful from C had it simply been able to pass through B (now defunct). If C’s work was expensive to perform, that’s a big loss due to an otherwise unrelated outage.
In this case, a retry might fix it, but will trigger the entire process from the beginning. This is not bad by itself, though. Retries are going to be required in any real network, because network failures are right up there with death and taxes: they are going to happen eventually to everyone, and probably sooner than anyone would like. But it obviously isn’t great.
Furthermore, the client itself might die, forgetting that it wanted something done. The eventual response gets dropped on the floor and forgotten in that case.
Another issue is that load balancers are required for scaling in synchronous systems. Load balancers are wonderful, and well understood technology, but they do introduce additional system complexity and, depending on your needs, may need you to cooperate with them (e.g., with health endpoints and startup/shutdown announcements). Multiply that by the number of different microservices, and it can get unwieldy.
The Ugly
Latency is the real issue here, in particular unpredictable latency. Latency, in this case, is “how long it takes a request to come back”. Service A is now dependent on two separate latency paths, which tend to compound how variable its wait time is: it is stuck with the worst case behavior of multiple services, now. That means it has to drastically increase its allowed timeouts or it runs the risk of missing a much higher percentage of successful answers when it gets tired of waiting. Variability tends to be additive in these systems.
Asynchronous Design
There is one fundamental principle of asynchronous design that is often missed, but is fortunately easy to state and remember:
In an asynchronous system, there are only requests. There are no responses.
There are, of course, subtleties that make this statement only approximately true, particularly as you work with outside systems that are beyond your control. For the sake of designing your own system using microservices, however, this statement is fine. Note that we’ll still think about some things as semantically being responses, but they are implemented as requests.
Consider the multi-service diagram from before, where a request from A to B waits on a sub-request from B to C to be fulfilled before it can get its final answer. In an asynchronous system, because there is no such thing as a response, there is no waiting: everything that sends a request does so without pause. The request becomes “fire and forget”. Now, instead of a chain of requests and responses, we merely have a chain of requests.
How, though, is this accomplished? There are a couple of common approaches. Let’s start with the simplest of them, and then move on to a better way that requires just a little bit more infrastructure. Here’s the first, obvious approach: just make all clients into servers.
Everything is a Server

In this setup, every client is also a server. Service A exposes an endpoint, and tells Service B where to send its “response”, which ends up being formed as a request to Service C. Eventually, all of that context makes its way back through the system (though it’s important to note that there might not be any reason for Service B to get in the way; Service C could send directly to Service A if Service B doesn’t need to do any processing first). A similar approach is applied everywhere in the system: nobody waits for a request, rather everyone exposes an endpoint where responses should be sent as requests. These endpoints are often communicated as “callback URLs” passed with the request itself. The service receiving the request knows where to send the results based on the included callback URL.
The big change from a synchronous architecture is that nobody is waiting. They fire off requests that contain enough information for responses to arrive (callback URLs), and they forget about it. Services therefore become even more stateless; the requester does not, indeed cannot, keep anything in the request thread’s memory to handle a later response without doing some torturous gymnastics. Instead, the response needs to contain enough context for the requester to know how to handle it.
What is a Response?
There is, however, a problem to be solved here. Information about the response target (the callback URL) must make its way through the entire system. In a synchronous environment, that information can just be “remembered” by the requester while it waits around.
The central component in the diagram (Service B) is where this becomes most evident. In a synchronous system, it has a thread—with its own memory—that is paused while it waits for a response from Service C. After it gets a response, that thread resumes, the response is processed, and then it remembers where to send its own response by virtue of it being part of the request thread’s memory. The audience for its reply was never forgotten, just put on hold.
In an asynchronous design, the audience for a reply has to be encoded into the context of the outgoing requests, so that when they come back, it is clear where to forward them. This can be done in several ways, including keeping session tokens, mapping request IDs to ultimate destinations, and others, but every one of these designs requires some information to be embedded in outbound requests, otherwise the final destination of the results is lost.
This is the part where people get a little lost. What, they wonder, is the actual context of the request, and how can I trust that the downstream service will remember it appropriately for me?
The answer is usually policy and coordination: asynchronous microservices have to cooperate on this crucial matter. They must agree how to send enough of the right kind of context beforehand. This is actually true, by the way, of any stateless service, including synchronous web servers: they rely on certain communication contracts, such as the semantics of cookies, to keep context. In the asynchronous case we need similar contracts to be established and adhered to, for the same reason.
If services are not cooperating in this way, they cannot (typically) communicate asynchronously. It’s part of the deal: if you are on the hook to send a response, but can only do it after you get one yourself, you need to make sure to keep enough context to do your part.
It’s all about context.
Complexity Everywhere
Another significant brain-breaking aspect of the “everyone is a server” model is the fact that fault tolerance is now everyone’s job. After all, if the system is not fault-tolerant, humans will have to be tolerant of faults, and we usually aren’t. How, for example, do we make sure that a single crash doesn’t cause outstanding work to be forgotten? In the above diagram, we really don’t, at least not without a lot of burden placed on every developer of every microservice. Yes, some of this can be hidden behind libraries, but there are problems with that approach as well (including version skew and uneven application of policy). We will talk in a moment about how to solve this, but for right now we just want to understand it.
In order for a service to be truly tolerant to faults downstream (in other services that are helping it with requests), it must take great care to persist context and to do things in a very particular order (as well as adhering to the “all global mutations must be idempotent” principle, which applies in every case, not just this one). Here is an example of a set of steps a client might take to ensure that it can retry a request properly, without losing work:
Pre-request:
Generate a request key,
Package the request with that key and its request data, including context, and
Store request data in persistent storage, with a flag indicating status (sent).
Make the request:
Send the package to the recipient (e.g., B -> C) and forget about it.
Then, because this is asynchronous, sometime later the client receives a “response request” (no responses, only requests!):
Receive downstream information (e.g., C -> B):
Mark state “finished” in persistent storage for the request’s key (from context).
Process and send response:
Formulate response for upstream requester, and
Atomically delete finished downstream entry and push upstream (e.g., B -> A).
Clearly this is a pain, and it isn’t even fully guaranteed that work will not be lost, because there are race conditions hiding between the persist and send steps. There are race conditions everywhere, actually.
Each service is also responsible for a new set of duties during startup. After a crash, every microservice must initialize itself by looking for and picking up unfinished requests from persistent storage to ensure that they are retried.
But what happens if there are other instances of this same microservice, and they are already in the middle of working on those unfinished requests? There is a real danger of sending requests multiple times.
In order to handle that particular thorny issue, the request database entry would need more information in its status. It needs to know who is working on it (a unique claimant ID, for example), how long it has left before it can be picked up by someone else, and what its current version is, so that two warring workers don’t both try to delete it at the same time.
That’s a lot for every single microservice in your system to be tracking! Furthermore, it looks a lot like—in order to really handle atomic changes to a response and a request—we will likely want everyone to use the same database! The amount of work, of course, isn’t the real issue. The real issue is the subtlety of that work: every microservice has to carefully and universally implement a subtle data dance to ensure fault tolerance.
This brings us to the real way to handle these situations: outsource fault tolerance and make it part of the system itself instead of a piece of all of the microservices within it.
Actually, Everything is a Client
It is possible to accomplish reasonable fault tolerance with the responsibility for it spread out across all of the microservices in a system, particularly if you can be guaranteed that they all use the same language and communication libraries by policy, and that those libraries are kept up to date everywhere. This is usually too much to require, however, because systems evolve, and one of the stated benefits of using microservices in the first place is that pieces of the system can evolve independently, to some extent. That means, among other things, that you might want to switch languages partway through while only reimplementing one microservice at a time. While going through that process, the system needs to keep running, even though most of it is in a deprecated language, using deprecated fault-tolerance libraries.
To make it easier for microservices to do the right thing, and to simultaneously allow better evolution of a system over time, we can outsource many of the concerns of fault tolerance. We do that with a fault-tolerant work management system as a core component, shared by all microservices. Note that there are many of these in the wild, but they are of highly variable quality, and most popular ones are designed around message delivery rather than fault-tolerant work management. This means they work most of the time, but are not configured by default for this situation ("competing consumers"), are not easy to configure correctly for this situation, and may have some corner case behaviors that trip folks up. Nearly all of them will cause work duplication or work loss in some situations, and those situations will eventually happen, because network errors are like death and taxes.
Most people we have spoken with tend to run into those situations rarely enough that they feel comfortable recommending Kafka, NATS.io, Redis, or RabbitMQ (to name a few) for this purpose. We feel less comfortable with that because of character-building experience (read “battle scars”, because even rarely losing work is problematic), but are aware that there are ways to make these systems dance for you.
The principles of a good work management system are outlined in the Google’s Site Reliability Engineering chapter on data pipelines, specifically the Google Workflow system. Our favorite system for this is EntroQ, and we meticulously designed it based on those principles. We will assume that interested parties will do the relevant reading there. Fortunately, you don’t need to know how they work if you just want to use them.
And use them, we will. Let’s look again at our multi-service system, but this time with a central work manager in the mix:

In this setup, every microservice becomes a task processor instead. Each of these task processors is strictly a client, not a server. Each task processor subscribes to one or more queues (“topics” in some circles) and receives work from them as they can handle it.
We have basically turned the whole “everyone is a server” situation upside down: now everyone is a client and there is just one server. Clients subscribe to work, and the server manages that work so that only one client can have a piece of it at a given time.
Each client uses a standard communication protocol to claim a task from a queue in the work management system. These are the standard operations that can be performed:
Claim a task: only one worker will succeed at taking that specific task, and the work system will keep track of who owns it and for how long.
Modify a set of tasks: this includes deleting and inserting, as well as changing things like expiration time on a task to retain ownership when things are taking a while but still progressing.
There are other read-only operations, like listing queues and tasks, but the two above are the foundation of the system. A worker can subscribe to a queue and be notified when something comes in for it to work on, and it can make changes to its own queue and insert tasks into others as atomic bulk operations.
Both claims and modifications are mutating events. This is important for reasons laid out in the SRE Book data pipelines chapter, as well as on the EntroQ home page, but that we won’t get into here. The important thing to note is the following:
Claims are exclusive: no two workers can hold a valid claim to the same task.
Modifications are atomic and persistent: multi-task operations succeed or fail together.
All operations fail that reference a non-existent task ID or version.
Having this system in play completely offloads the responsibility of managing tasks, taking it away from the “microservices” (now task processors) and placing it onto a central system. Now, a task processor can simply claim a task when notified, do work, and push tasks for other processors to accomplish.
The principle of “there are only requests” still applies here, but now it’s turned around. Everyone is requesting from the work manager, and it is the only server in the system.
This approach has many benefits:
Scaling up is as simple as creating new replicas. Scaling down is simple, too.
System topology is more fluid at runtime, not quite as predetermined at startup.
Fault tolerance is built in: crashes leave tasks behind to be claimed again later.
Duplication is designed out: tasks are managed by the service, not the processor, and no two workers can successfully acknowledge the same task.
The astute reader will notice, however, that we just created a new single point of failure: we have to manage this work management system, and it has to stay up and handle potentially a lot of traffic. These are valid concerns, and there are some valid, though nuanced, responses:
The persistent nature of tasks means that the work manager will restart quickly and gracefully if it crashes, is evicted, etc.
Designing around larger tasks instead of smaller ones is highly recommend, and means that
A work manager restart is less likely to cause disruption (it can happen while a task is still being processed), and
More expensive tasks mean less traffic load on the work manager.
If your tasks are tiny, that means they are also cheap to simply repeat when they fail. You really don’t want a work manager in that case; you want a function call.
Good advice and thoughts about this are again available in the SRE chapter on data processing pipelines, and that remains highly recommended reading.
With all that, however, there is still another useful step to take, making this even simpler for developers, while also keeping it nimble in case central technologies (like the work manager itself!) need to change.
Never Mind, Everything is a Server Again
The big downside to using a new central service to manage “microservice” (task processor) tasks is that now every task processor has an explicit code dependency on a particular piece of technology, and they must be designed around queue management and its own potentially esoteric protocols and behaviors.
This is unfortunate, because queue systems come and go, and sometimes you want to swap them out. We have seen many examples of environments, for example, where Kafka was not precisely serving the needs of an organization, but they couldn’t afford to change it because literally every piece of processing code had a direct library dependency on Kafka. That’s not a good plan.
This can be avoided by applying one more transformation to the system:
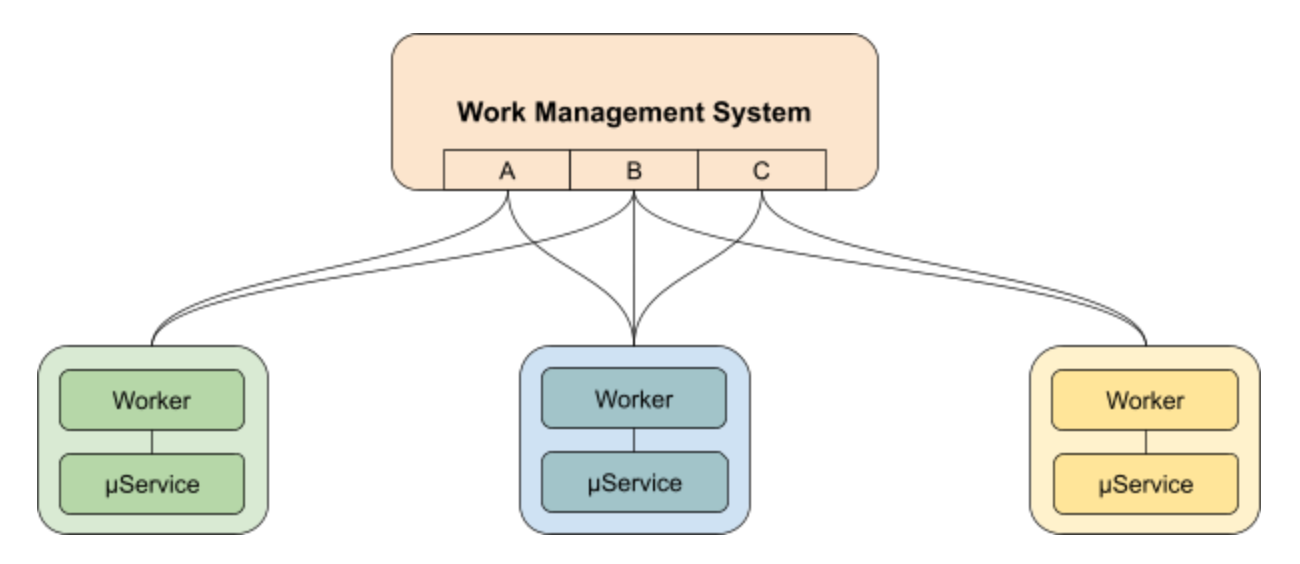
In this layout, each of the task processors is back to being a service, labeled “μService” in the diagram. It is deployed next to (or as a child process of, depending on cluster implementation) a worker that is responsible for claiming tasks and forwarding them to the corresponding microservice. Thus, developers can simply create microservices as before, but are completely shielded from the specifics of the queue management technology.
This technique is commonly applied in functions-as-a-service (FaaS) strategies for Kubernetes, for example, where the “worker” is a sidecar within a pod, and is deployed with each microservice instance. In some cases, such as systems that use Istio and the Envoy Proxy, these sidecars are deployed transparently. However deployed, the principles of their operation remain the same: there is a separate process obtaining tasks and sending them to a microservice.
In this environment, it is still important to think asynchronously about how to design the system. You still need to manage context, and microservices still need to pass it through, but you no longer need to know or care about the fact that a work queue is in play, or what specific technology is used to implement it.
A carefully designed worker can manage parallelism to the microservice, renew claims while the (now backend, but local) request to the microservice is waiting to be fulfilled, and handle deletion of the task only when the microservice finishes servicing it. A worker is also a proxy of sorts: unsolicited requests from the microservice can be transformed into tasks by the worker, upon request.
The microservice itself becomes more synchronous in this scenario than before: it can do processing while the worker waits for it, and it doesn’t impact the resources of its neighbors by holding open their connections. The only impact is to its own personal worker. Furthermore, while a worker is waiting, it can drop its subscription to the work manager, renewing it only when another task is needed. These and other system-level optimizations become easier when system designers are responsible for system communication, rather than microservice designers.
Because contracts are needed around context, we like to impose a particular set of simple semantics on microservices:
Each microservice accepts and produces Cloud Events, where
type is taken to be the name of the microservice, also the name of its queue.
subject is the microservice HTTP path to which the worker should send a task.
Some Cloud Event extensions are also in play:
authtoken contains an authorization token, and must be passed along to others.
responsetype is the microservice name to which a response is requested.
responsesubject is the microservice HTTP path on which to send the response.
If subrequests are to be made, they should be returned as the HTTP response of the microservice, as a concatenated set of cloud events with appropriate types and subjects.
In the event that a response is desired and sub-requests are needed, the sub-requests are returned immediately, and the microservice is responsible for setting their context up such that when they come back, it has enough information to push out a final response. Unfortunately, cloud events do not allow non-header extensions, so specifying a context extension can help, but limits the amount of information that can be in the context. Usually some policy about payload has to be employed for this to work.
With these in play, it is not only possible to represent all kinds of asynchronous systems, it is relatively easy to do so without placing an undue burden on the microservice developers, where the true business logic typically resides. It separates fault tolerance out into a separate, carefully maintained system, and it isolates business logic from details about where things are in the cluster and how tasks are being managed.
Bringing It All Together
The fundamental principle of asynchronous communication in a microservice-oriented system is simple to state: there are no responses, only requests. This remains true for various approaches to implementing such systems, but some implementations have clear advantages.
Whichever implementation is your favorite (we definitely have our own!), thinking about the fundamentals is always required:
Requests are “fire and forget”: there are no waited-for responses.
Every request needs context to ensure data ends up where it needs to be.
So long as those principles are followed, you can design a fairly successful asynchronous system. If you want it to be really successful, you can add this:
Fault tolerance is crucial, but really subtle and better outsourced.
Make life easy on developers: isolate them from large system choices.
We have found in our own experience that the application of these principles, and learning to think this way about some of our larger systems, has made a level of fault tolerance and recovery possible that simply wasn’t in other circumstances. We hope you do, too!