AUC VS LOG LOSS
By Nathan Danneman and Kassandra Clauser
Area under the receiver operator curve (AUC) is a reasonable metric for many binary classification tasks. Its primary positive feature is that it aggregates across different threshold values for binary prediction, separating the issues of threshold setting from predictive power. However, AUC has several detriments: it is insensitive to meaningful misorderings, is a relative measure, and does not incentivize well-calibrated probabilities. This brief describes these issues, and motivates the use of log loss as an evaluation metric for binary classifiers when well-calibrated probabilities are important.
AUC functionally measures how well-ordered results are in accordance with true class membership. As such, small misorderings do not affect it strongly, though these may be important to an intuitive sense of the performance of an algorithm. This means that, for some definition of “important”, it is possible for AUC to completely mask important misorderings: there is no sense of “how far off” something is in terms of its AUC.
AUC is a relative measure of internal ordering, rather than an absolute measure of the quality of a set of predictions. This hinders interpretability for downstream users. Furthermore, machine learning (ML) systems that use the output of other ML systems as features already suffer from performance drift; but this is greatly mitigated by restricting the output range of those upstream systems, and by using calibrated values. These two constraints make ML system chaining far more likely to produce valid results, even as the input systems are retraining. Proper calibration can be incentivized naturally by using a calibration-sensitive metric.
Log loss is another metric for evaluating the quality of classification algorithms. This metric captures the extent to which predicted probabilities diverge from class labels. As such, it is an absolute measure of quality, which incentivizes generating well-calibrated, probabilistic statements. They are easier to reason about for human consumers, and simpler to work with for downstream ML applications. Furthermore, like AUC, log loss is threshold-agnostic, and is thus a comparison of classifiers that does not have to pick decision threshold.
Overall, in cases where an absolute measure is desired, log loss can be simply substituted for AUC. It is threshold-agnostic, simple to compute, and applicable to binary and multi-class classification problems.
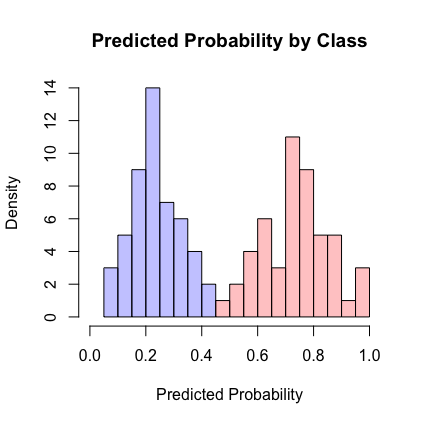
The picture here shows a hypothetical distribution of predicted probabilities by class. An example of good separation but low predictive power. You get great AUC but crummy logloss.